‘튜링 테스트(Turing test)’는 인공지능(AI)이 인간과 동등한 지능적 행위가 가능한지, 실제 사람을 대신할 수 있는지 여부를 보는 시험이다. ‘이미테이션(모방) 게임’으로도 불린다. 영국의 수학자이자 컴퓨터 과학자인 앨런 튜링이 1950년 제안했다.
지난 3월 31일(현지시각) 미국 샌디에이고 캘리포니아대(UCSD) 연구진은 출판 전 논문 공유 사이트인 arXiv에 논문을 게재했다. GPT-4o, LLaMa-3.1-405B, GPT-4.5 가운데 1개 모델이 압도적 승률로 튜링 테스트를 통과했다는 소식을 알리면서 눈길을 끌었다.
튜링 테스트는 무엇?
튜링 테스트는 끊임없이 논쟁의 대상이 된 시험이다. 과연 진정한 지능이나 의식을 측정할 수 있냐는 비판과 함께 AI가 인간과 의사소통이 가능한지 객관적으로 측정할 수 있는 시험이라는 주장이 공존한다.
물론 인간의 지적 능력에 대한 명확한 정의가 없고, 통제된 환경이 갖춰져야 한다는 등 여러 한계점이 있다. 이견이 없는 부분은 튜링 테스트는 그동안 AI 개발자에게 큰 과제였다는 것이다.
튜링 테스트도 꾸준히 발전해왔다. 처음엔 인간과 컴퓨터를 두고 질문자가 대화 이후 어느 쪽이 컴퓨터인지 판단할 수 없다면 시험을 통과한 것으로 봤다. 이후 시각과 청각을 따로 평가하거나 이를 동시에 평가하는 멀티모달 테스트를 넣기도 했다.
테스트 통과는 이전에도 있었다?
2014년 영국 레딩대가 튜링 테스트를 처음 통과한 사례가 나왔다고 발표했다. ‘유진 구스트만’이라는 슈퍼컴퓨터에서 돌아가는 ‘유진’이라는 프로그램이 이 기준을 통과했다는 것이다. 앨런 튜링 별세 60주년을 기념하기 위한 자리였다.
당시 행사 조직위는 유진이 5분 길이의 텍스트 대화를 통해 심사위원진 33% 이상에서 인간이라는 확신을 줬다고 밝혔다. 그러나 유진 프로그램을 13세 소년으로 설정하고 사람들과 대화를 나누도록 했다. 뭔가 모르더라도 사람들이 넘어갈 수 있도록 캐릭터를 만든 것이다.
지금 시점에서 보면 튜링 테스트 통과가 맞는지 반문할 법하다. 이전에도 튜링 테스트 통과를 주장한 사례가 있었다. 당시 행사 조직위는 “이전에도 튜링 테스트를 통과한 사례가 있다고 주장할지 모르지만”이라고 언급하면서 이번 테스트가 독자적 검증이 이뤄졌고, 미리 질문을 정해놓지 않는 등 대화 내용에 제한이 없었던 점을 미뤄 진정한 튜링 테스트의 통과라고 의미를 부여했다. 시대상에 맞춰 튜링 테스트도 변화해온 셈이다.
이번은 달라
UCSD는 2024년에도 튜링 테스트 통과 사례를 공유한 바 있다. 500명을 모아 4그룹으로 나눠 인간, GPT-4, GPT-3.5와 대화하도록 진행했다. 고전 챗봇 모델인 엘리자(ELIZA)도 포함했다.
당시 인간으로 식별한 비율인 합격률은 ▲인간 67% ▲GPT-4 54% ▲GPT-3.5 50% ▲ELIZA 22%였다. UCSD 인지과학 연구팀은 인간보다 합격률이 떨어지더라도 무작위 추측 확률인 절반(50%)을 초과한 GPT-4가 튜링 테스트를 통과했다고 봤다.
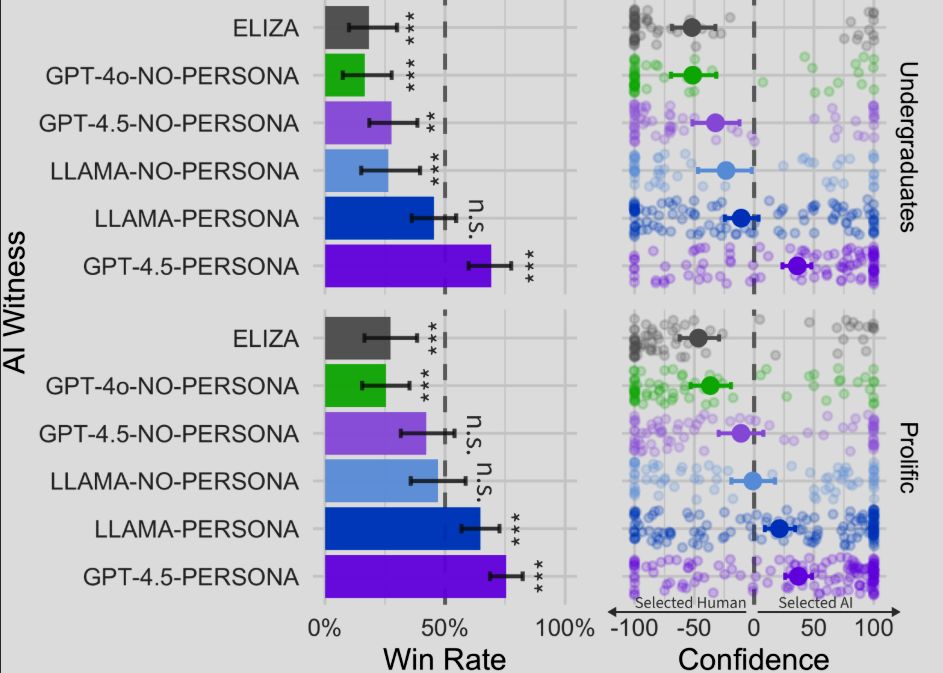
얼마 전 발표한 UCSD 테스트는 좀 더 고도화됐다. 3자 간 대화를 적용했고, 최초로 이를 통과한 AI가 나왔다. 질문자는 인간 참가자, 컴퓨터와 5분간 대화를 나눈다. 질문자가 누가 인간인지 구별하지 못하거나 컴퓨터를 인간의 답변으로 착각하면 튜링 테스트를 통과한 것으로 봤다. 1라운드 당 1개의 메시지를 보내 8라운드를 진행, 총 1023개 테스트를 분석했다.
이번 튜링 테스트는 인간과 유사한 페르소나(성격)를 지시한 것이 특징이다. 이러한 지시를 받은 GPT-4.5는 73%, LLaMa-3.1은 56% 확률로 ‘사람 같다’는 평가를 받았다. 페르소나 지시를 받지 않은 GPT-4.5와 LLaMa-3.1은 각각 36%, 38%로 무작위 추측보다 합격률이 훨씬 떨어졌다. 기준 모델인 GPT-4o와 ELIZA도 각각 21%와 23%로 낮은 합격률을 보였다.
지능 테스트 아냐
튜링 테스트는 지능 자체를 측정하는 시험이 아니다. 인간과 얼마나 비슷한지 시험하는 것이다. 질문자는 언어 스타일과 감정 표현, 지식, 상황 인식 등을 종합 고려해 인간 여부를 판단했다. 지능과 관련한 추론보다는 정서적 요인에 따라 인간 여부를 판별할 가능성이 높게 나타났다.
점차 AI에 대한 신뢰도가 높아지면서, 똑똑한 답변일수록 AI로 판단하는 상황이 나타나기 시작했다. 이 때문에 인간이 똑똑하게 답변하면 AI로 착각하는 사례가 나왔다. 반면 예상치 못한 답을 내거나 인터넷 속어를 쓰고 친근하게 반문하는 등의 매력적인 반응을 보이면 AI를 인간으로 착각했다. 페르소나형 AI의 합격률이 높은 이유다.
튜링 테스트도 발전 중
현재 튜링 테스트를 어떻게 구현해야 하는지 명확하게 정해진 것은 없다. 테스트 시간이나 참가자를 어떤 집단으로 구성해야 할지, 전혀 모르는 사람으로만 모집단을 구성해야 할지, 참여자에게 인센티브를 제공해 더욱 차별적인 행동을 유도할지 등 계속적인 연구가 이뤄져야 한다.
그에 따라 AI 모델의 정확한 성능을 예측할 수 있는 튜링 테스트의 필요성도 언급되고 있다. 이번 사례로 프롬프트 엔지니어링이 튜링 테스트에서 영향을 미치는 것이 입증됐다. 지능은 복잡하고 다면적이다. AI가 모방하기 어려운 사회적 개념도 테스트의 기준이 될 수 있다.
글. 바이라인네트워크
<이대호 기자>ldhdd@byline.network
!["무역전쟁 승자없어" 習, ‘관세폭탄’ 맞은 베트남 찾았다…현대차·기아, 美판매가 인상 추진 [AI 프리즘*기업 CEO 뉴스]](https://newsimg.sedaily.com/2025/04/15/2GRJ54CZVF_1.jpg)

![[헬로티 TOP 10] 3월 글로벌 머신비전 시장이 주목한 신제품 TOP 10](https://www.hellot.net/data/photos/20250416/art_17446767376829_b51844.jpg)