한국전자통신연구원(ETRI)이 한국어를 학습한 30억 파라미터(매개변수) 규모의 소형언어모델(SLM) ‘이글’을 허깅페이스허브에 공개했다고 28일 밝혔다. ETRI는 비용 부담과 한국어 학습 한계로 글로벌 빅테크의 언어모델을 쓸 수 없는 국내 중소·중견기업에게 이글이 유용하게 쓰일 것으로 기대했다.
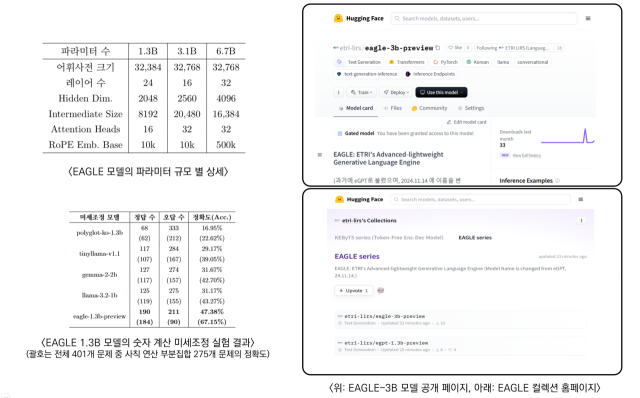
ETRI는 기존 언어모델들보다 한국어 학습과 처리 효율을 높이는 데 주력했다. 이를 통해 학습시간이 기존보다 20% 단축되는 등 한국어 성능 향상을 이뤘다. 4월 공개한 13억 파라미터 모델은 글로벌 기업들의 모델들보다 규모가 절반인데도 특정 작업들에서는 15% 높은 성능을 보였다.
기존 모델들은 한국어 어휘를 음절이나 바이트 단위로 처리하기 때문에, 동일한 문장을 표현하는 데 영어보다 더 많은 연산이 필요하다. 또 학습된 데이터 중 한국어 비중은 5%에도 못 미친다는 한계가 있다고 ETRI는 설명했다.
ETRI는 신경망 기초 모델이 개념 표현을 효과적으로 습득할 수 있도록 하는 추가 연구를 진행하고 있다. 기초 모델의 표현 품질을 예측할 수 있는 기술과 개념 단위로 조합해 추론할 수 있는 원천 기술도 함께 개발하고 있다.
ETRI는 또 70억 파라미터 규모의 모델과 사전 정렬을 통해 추가 학습 없이 사용자의 요청에 맞게 응답을 수행할 수 있는 모델도 내년에 순차적으로 공개할 예정이다. 초등학교 수학을 지원하는 교사용 튜터 개발에도 힘쓰고 있다.

![[나노종기원, Al 기반 반도체공정 예측 시스템 개발] 공정 결과 예측·최적화 실현…중소기업 R&D '천군만마'](https://img.etnews.com/news/article/2024/11/27/news-p.v1.20241127.352875c712294a408c685da0483167bd_P1.jpg)
![[SHAPER AtoZ 2] 제조기업부터 개인까지...맞춤형 데이터 솔루션 구축](https://www.hellot.net/data/photos/20241148/art_17326668532197_89196e.png)
![[人사이트] 이경수 엑스코어시스템 사업본부장 “영세 식품기업 디지털 전환, 스마트센서 기술력으로 선도”](https://img.etnews.com/news/article/2024/11/28/news-p.v1.20241128.1f08b426d0174c8b8c82e4e69853ad4f_P2.jpg)
![[인터뷰] 엠에이치에스 "'초소형 수냉식 냉각 기술 개발... AI 반도체 최적 냉각 솔루션"](https://img.newspim.com/news/2024/11/27/2411270049500160_w.jpg)