한국지능정보원
품질검증 거친 833종 데이터 구축
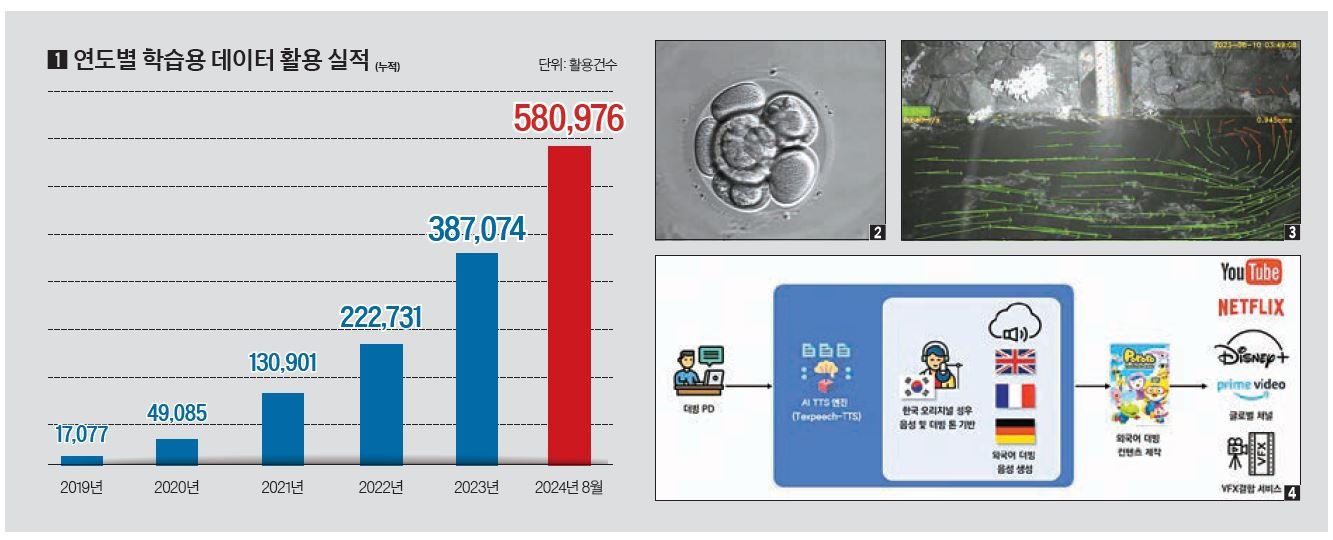
340만명 방문, 이용 건수 58만 건
삼성 등 빅테크도 적극 활용 주목
2022년 11월 OpenAI의 ‘ChatGPT’ 등장 이후 인공지능(AI)이 일상화하면서 데이터의 중요성이 커지고 있다. AI 성능은 학습에 사용된 데이터의 양과 질에 따라 좌우되는데, 중소기업·스타트업·연구계 등은 활용 가능한 데이터를 확보하는 데 어려움을 겪고 있다. 이러한 상황에서 과학기술정보통신부(과기정통부)와 한국지능정보원(NIA)은 ‘AI허브’를 통해 인공지능 학습용 데이터를 구축하고 개방하며 AI 혁신을 선도하고 있다.
과기정통부와 NIA는 데이터 확보 문제를 해결하기 위해 국내 최대 AI 학습용 데이터 제공 플랫폼인 ‘AI허브’를 운영하고 있다. 현재까지 총 833종의 데이터가 구축됐는데, 저작권과 개인정보 문제를 해결하고 전문기관의 품질 평가를 거친 검증된 데이터다. 2024년 8월 말 기준으로 데이터 활용 건수는 약 58만 건에 달하며, 방문자는 340만 명 이상이다. 특히 중소기업·스타트업·학계·개인들이 활용한 한국어 텍스트와 음성 데이터가 46만 건을 넘었으며, 이는 AI 기술 발전에 크게 기여하고 있다.
삼성·LG·네이버·SK·KT 등 빅테크 기업들도 대규모 언어모델(LLM) 고도화와 AI 서비스 개발에 이 데이터를 적극적으로 활용하는 것도 주목할 만하다. 이는 AI허브가 제공하는 데이터의 품질과 다양성이 업계 표준에 도달했음을 시사한다.
과기정통부와 NIA는 올해 들어 AI허브 사업을 ‘초거대 AI 확산 생태계 조성 사업’으로 전환해 생성 AI의 파급효과가 큰 핵심 분야를 중심으로 70종의 말뭉치 및 멀티모달(multimodal:다양한 형식의 데이터를 함께 처리하는 것) 데이터를 구축하는 일에 매진하고 있다. 특히 주목할 만한 점은 재난·의료 등 데이터 확보가 어려운 분야에서 8종의 합성데이터를 공공부문 최초로 개방했다는 것이다.
또한 과기정통부와 NIA는 버티컬 AI를 위해 전문 분야별 특화 데이터 구축 계획을 마련하고 있으며, 기존 구축된 멀티미디어 데이터를 멀티모달 데이터로 개선하고 원본 데이터 활용 가능 체계로 고도화할 예정이다. 이는 AI 개발을 촉진하고 한국 기업의 경쟁력을 높이는 데 기여할 것으로 기대된다.
NIA는 데이터 제공뿐만 아니라 AI 모델 성능 개선에도 힘쓰고 있다. LLM 전문기업 업스테이지와 협력해 국내 최대 개방형 한국어 LLM 평가 체계인 ‘Open Ko-LLM 리더보드’를 운영하고 있으며, 1700개 이상의 LLM 모델이 참가했다. 이를 통해 AI 기술 발전을 가속하고, 국내 AI 기업들의 글로벌 경쟁력을 강화할 것으로 기대된다.
NIA 황종성 원장은 “NIA는 데이터·인공지능 전문기관으로서 과기정통부와 함께 인공지능 발전에 필요한 데이터 및 데이터 유통·활용 인프라를 지속해서 발전시켜 나가겠다”며 “특히 AI허브가 한국의 AI 기술 혁신을 이끄는 핵심 동력이 될 것임을 확신하며, AI 기술 발전과 경쟁력 강화의 중추적 역할을 할 것으로 기대한다”고 말했다.
![[황보현우의 AI시대] 〈15〉신지식재산의 산업화를 위한 공감대가 필요하다](https://img.etnews.com/news/article/2024/09/25/news-p.v1.20240925.4b515daac88e4df48c6c3947793b2923_P1.jpg)





