Factpl original
AI 학습지 된 네이버 데이터
크롤링 2차 공방전
이 정도면 ‘메이드 인 판교 AI’보다 낫다고? 요즘 실리콘밸리산(産) 빅테크 AI, 한국 사정과 한국어에 빠삭하다. 소버린 AI(각국 독자적 AI)로 불리는 국산 AI가 아쉽지 않을 정도. 쇼핑, 블로그, 부동산, 지식인, 증권 등 AI 훈련에 필수인 방대한 한국어 데이터베이스(DB)를 두루 가진 네이버 입장에선 선뜻 의심을 거둘 수 없다. ‘우리 데이터 가져다 쓴 거 아냐?’ 심증은 있어도 물증은 없다.
네이버는 결단을 내렸다. 지난 달부터 모든 웹페이지에 AI 크롤링(온라인상 데이터 수집)을 차단하는 코드를 적용해 빅테크 AI가 자사 데이터를 긁어가는 길목을 전면 차단한 것. 그런데 이런 갈등, 처음은 아니다. 구글, 오픈AI 등은 때로는 서로가, 때로는 언론사나 크리에이터 등 콘텐트 창작자와 크롤링 갈등을 벌였다. 지금 데이터의 권리를 주장하고 있는 네이버도 언론사 기사를 AI 학습에 활용한 대가를 제대로 치르지 않았다는 비판을 받고 있다. AI 시대 전면전 양상으로 치닫고 있는 ‘크롤링 전쟁’. 빅테크와 네이버 간 승자는 누굴까. 빅테크 기업의 내로남불 결말과 크롤링의 미래는.

1. 빅테크 침공, 철벽 방어 나선 네이버
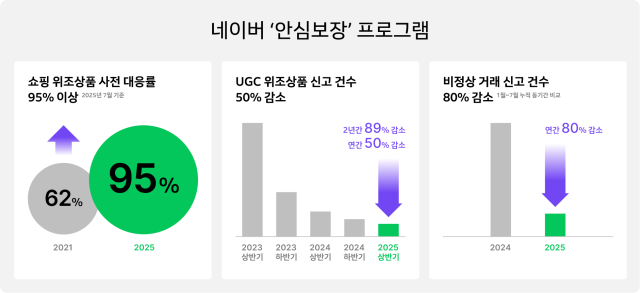
①네이버의 데이터단속
어디 감히 데이터를 : 네이버는 6월 넷째 주부터 7월 첫째 주까지 순차적으로 네이버의 모든 서비스에 AI의 크롤링을 차단하는 코드를 적용했다. 이전까지 쇼핑, 부동산, 블로그 등 일부 서비스에 적용하던 것을 모든 서비스로 확대했다. 뿐만 아니라 실시간으로 정보를 외부에서 검색해 답변을 생성하는 외국산 AI의 검색증강생성(RAG)도 전면 차단했다.


![엔비디아 AI칩 중국 판매 재개됐지만... “회복 어려울 것” [디지털포스트 모닝픽]](https://www.ilovepc.co.kr/news/photo/202508/55558_151667_1414.jpeg)


!["왜 카카오만 또"…상승장 속 카카오만 '나홀로' 하락한 이유[이런국장 저런주식]](https://newsimg.sedaily.com/2025/08/05/2GWIA3JJYK_1.png)
![[기자의눈] 구글이 져야할 마땅한 책임](https://newsimg.sedaily.com/2025/08/04/2GWHVIFGY3_1.jpg)
![팀 쿡, AI 검색 승부수… 애플 '앤서'팀 구축 [윤민혁의 실리콘밸리View]](https://newsimg.sedaily.com/2025/08/04/2GWHUK2PC5_1.png)