
정보기술(IT) 시장에 관심 많으신 독자 여러분, 안녕하세요. 제가 사회 생활을 길게 한 건 아니지만 이런 설 연휴는 처음입니다.
딥.시.크. 최첨단 테크 이슈가 온 명절을 뒤덮는 느낌은 정말이지 생경합니다. 이번주 한국의 달력은 온통 빨강색인데 이 중국 AI 회사의 출현으로 미국 증시는 파랗게 물들었습니다. AI 반도체 대장 격인 엔비디아 주가는 27일(현지시간) 20% 가까이 폭락했죠.
29일 새벽 엔비디아 주가가 더 큰 폭으로 떨어지지 않는 걸 보면서 문득 궁금해지기 시작했습니다. 딥시크의 '저가형' AI는 엔비디아의 종말을 알리는 소식일까. 브로드컴 등 미국 반도체 회사들은 지금처럼 시장에 AI 칩을 팔지 못하는 것일까. SK하이닉스의 고대역폭메모리(HBM) 초호황기는 여기서 막을 내리는 걸까.
전문가의 목소리와 업계 곳곳에서 나오는 여러가지 분석을 토대로 봤을 때 '딥시크로 AI 칩 고도화의 종말을 예단하는 건 시기상조'일 듯 합니다. 지금부터 취재하고 공부한 내용을 소개하고자 합니다.
‘H800·FP8’…이걸로 오픈AI를 제쳤다고?
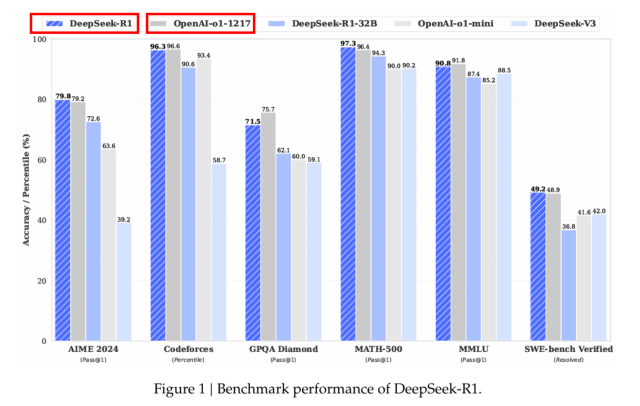
딥시크는 쇼킹하긴 합니다. 미국의 반도체 제재를 우회하기 위해 엔비디아가 일반적인 'H100' GPU보다 성능을 대폭 낮춰 중국에 공급하는 'H800'을 가지고도 이정도 성과를 냈거든요.


거기에 더 화제가 된 건 '부동소수점'입니다. [강해령의 하이엔드 테크] 독자 분이시라면 이 용어 친숙하실텐데요. 네이버와 삼성전자의 마하1 칩 개발에서 설명드린 적 있습니다.
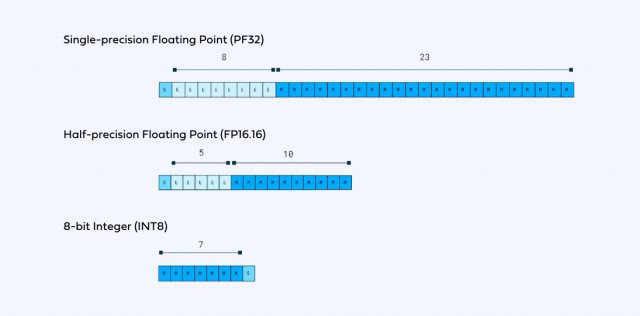
엔지니어들은 실수(real number) 기준 -3.40X10의 38승부터 3.40X10의 38승 사이에 있는 약 40억개의 십진법 수를 32개의 0또는 1, 즉 32비트로 표현할 수 있습니다. 이걸 부동소수점이라고 합니다. 32비트의 경우 ‘FP(Floating Point)32’라고 일컫기도 하죠.
부동소수점은 32비트로 나타낼 수도 있지만 압축을 해서 16비트(FP16), 8비트(FP8)로도 표현할 수 있습니다. 수를 압축하는 대신 단점도 생깁니다. 데이터가 간단해진 만큼 연산이 더 빨라지긴 해도 그만큼 정밀도가 상대적으로 낮아집니다.
자, 딥시크는 FP8에다 데이터 전송 속도가 매우 답답한 하드웨어인 H800을 썼고요. 이들의 라이벌인 오픈AI는 H100 이상의 최고급 GPU, 정밀도가 높은 FP16으로 거대언어모델(LLM)을 만들어냈습니다.
그럼에도 불구하고 가장 최근 공개된 딥시크의 R1 모델이 LLM의 업계 최고 스타인 오픈AI의 o1과 '온 파(on par)', 즉 거의 비슷하거나 심지어 더 뛰어난 성능을 냈다고 주장했고, 심지어 실체가 있으니 업계가 충격에 빠진 겁니다. 엔지니어가 AI의 연산에 개입해 더 나은 결과 값에 보상을 해주는 강화 학습(Reinforcement Learning), 고순도 데이터를 만들 수 있는 지식 증류(Knowledge Distillation) 등 기존 업체들이 시도하지 않았던 혁신적인 알짜 프로세스를 도입한 게 먹혀든 것으로 분석됩니다. 수년 간 거대한 투자를 해왔던 세계적인 AI 경쟁사들도 깜짝 놀랐다고 합니다.
진짜 78억 원 밖에 안들었다고?
문제는 비용인데요. 진짜 저렴하게 만든 AI가 맞는지에 대해 짚어볼 필요가 있습니다.
그간 언론에서는 R1 구현에 들어간 비용이 558만 달러(약 78억원)라고 보도했습니다. 업계에서는 미국 빅테크 AI 훈련 비용의 10%도 미치지 못할 만큼 커다란 혁신이 일어났다며 흥분했죠.
하지만 여기서 더 자세히 보고 넘어가야 할 부분이 있습니다. 우선 딥시크 R1은 AI 구현 단계에서 '추론'에 특화된 모델입니다. 기존 훈련 모델인 V3에서 미세 조정(fine-tuning)을 거친 모델인데요. 딥시크가 공식적으로 출간한 기술 리포트에서는 R1 구현에 78억 원이 들었다고 언급한 구절은 없습니다.

78억원이 들어간 곳은 R1보다 앞서 공개한 훈련 모델인 ‘V3’입니다. 2048장의 H800을 활용했다는 것도 V3를 구현할 때입니다. 따라서 V3에서 R1으로 넘어갈 때 얼마나 더 많은 추가 비용과 GPU가 들어갔는지는 확인이 힘듭니다. 한 AI 전문가는 "R1과 같은 추론 모델은 앞선 모델들의 출력 결과에 데이터를 재귀적(再歸的)으로 주입하는 게 일반적이다"라며 "따라서 앞선 모델 구현 비용까지 누적해서 계산한 것이 진짜 비용"이라고 설명했습니다. 78억+a 로 보는 게 맞다는 거죠.

더 석연찮은 부분도 V3 기술 리포트에서 보입니다. 딥시크는 V3 구현에 사용된 78억 원에 대해 "V3의 공식적인 훈련만 포함된 것이며, 사전 연구와 소거 실험에 관련된 비용은 포함하지 않았다"고 설명했습니다. 부분적인 비용에 불과하다는 걸 스스로 설명하고 있는 겁니다.
이런 관점에서 보면 딥시크가 R1를 구현하기 위해 78억 원에 R1 구현을 위한 추가 비용+V3 이전의 데이터 구축 비용 등 시장에 알려진 것보다 훨씬 많은 돈을 투입했을 것이고, 심지어 V3를 구현하기 전 모델을 구현하기 위해 H100을 수 만대 돌렸을 수 있다는 루머가 꽤 그럴듯하게 들리기도 합니다. 따라서 중국은 80억 원으로도 오픈AI 잘만 제친다, GPU 2000장만 있으면 LLM이 나오는 진정한 AI 대중화 시대가 왔다, 한국은 그동안 대체 뭐했느냐 등의 주장은 조금 더 지켜봐야 하지 않을까 싶습니다.
엔비디아·AI 반도체 업계는 이대로 절망해야 하는가

그럼 이제 우리의 최대 관심 사안인 엔비디아나 브로드컴은 이렇게 무너질 것인가에 대해 봐야겠습니다. 미래는 누구도 예상할 수 없지만 엔비디아 위기론은 너무 시기상조라는 쪽에 조심스럽게 무게를 실어봅니다. 두 가지 이유입니다.

우선 파격적으로 저렴한 모델을 선보인 딥시크도 고성능의 GPU와 HBM을 갈망하고 있습니다. 조금 전 말씀드린 V3 리포트를 보면요. FP8의 단점인 오차를 극복하기 위해서는 '34비트의 누적정밀도를 구현하는 차세대 GPU'가 필요하다고 언급하는데요.
챗GPT에게 취재해보니 현존하는 최고 GPU인 블랙웰도 이런 스펙은 구현 못한다고 합니다. 딥시크가 GPU 협력사 사명을 구체적으로 언급하지는 않았지만, 엔비디아를 향한 요구와 구애가 아닐까 추정됩니다.
HBM에 대한 이야기도 빼놓지 않았습니다. 2년 후에 본격적으로 꽃필 것으로 예상되는 커스텀 HBM을 시사하는 말도 있습니다. 이건 SK하이닉스 같은 HBM 강자들에게 힌트를 주는 메시지로도 읽힙니다.

두번째, 앞으로 미국에서 AI 군비 경쟁이 더 뜨거워질 가능성은 여전하다는 것입니다. 엔비디아와 IT 업계가 중국 AI 생태계의 출현에 긴장할 상황은 분명합니다. 다만 아직 추론 모델 고도화와 데이터 경량화에 대한 과제는 무궁무진하기에 앞으로 더 많은 투자가 있을 것이라는 전문가 의견도 상당히 많습니다. 미국은 중국을 반드시 꺾어야 하는 정치적 문제도 있기에, 더 비싸더라도 성능 좋은 GPU나 주문형 AI 칩으로 더 경량화한 모델을 빠르게 구현하고자 하는 의지가 있을 것입니다. 조만간 있을 MS, 메타 등 주요 AI 빅테크들의 실적 발표회에서 설비투자(CAPEX)에 대해 어떤 발언을 할지 업계가 상당히 주목하고 있습니다.
메모리 강자인 삼성전자와 SK하이닉스에도 마찬가지입니다. HBM을 활용하는 엔비디아 칩은 물론이고요. LPDDR D램 등으로 추론용 칩셋의 변화를 모색하려는 시장의 움직임도 감지되고 있어, 적극적인 시장 대응이 있으면 메모리에서도 충분히 기회를 만들 수 있을 것입니다.
당분간 딥시크의 출현으로 테크 업계가 상당히 분주해질 것으로 보이는데요. 열심히 딥시크와 AI 혁신을 체크하고 있다가, 따끈따끈한 소식 있으면 전해드리겠습니다.
새해 복 많이 받으시고 남은 연휴도 [강해령의 하이엔드 테크]와 함께 하세요.



![[설왕설래] 혁신으로 챗GPT 넘어선 딥시크](https://img.segye.com/content/image/2025/01/29/20250129503512.jpg)




