정부가 그래픽처리장치(GPU) 등 인공지능(AI) 인프라 논의를 지속하는 가운데 양질의 학습용 데이터 확보에도 관심을 기울여야 한다는 지적이 제기된다.
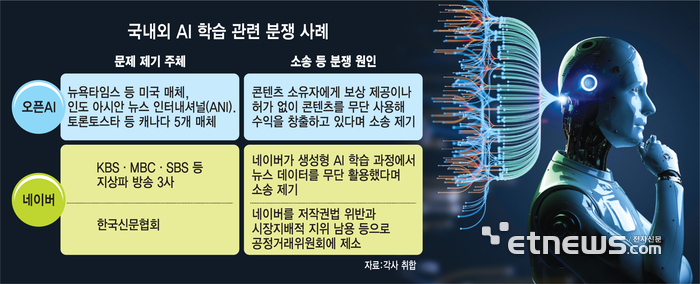
해외에서는 오픈AI, 국내에서는 네이버가 데이터 학습 관련 송사에 휘말린 상황에서 충분한 학습용 데이터셋 확보나 저작권 관련 명확한 제도나 기준 없이는 AI 기업 부담과 불필요한 논란이 지속될 것이라는 우려 목소리가 크다.
24일 AI업계·학계에 따르면 스타트업 등 AI 기업을 중심으로 고품질 데이터 확보에 대한 부담과 우려가 큰 상황이다.
국내 AI 기업은 웹사이트 크롤링(방대한 데이터 추출)·스크래핑(특정 정보 추출) 등으로 학습용 데이터를 확보하거나 아르바이트 구인을 통해 글과 사진·영상 등 단편적으로 학습용 데이터를 수집하고 있다.
그러나 이같은 방법으로 양질 데이터를 확보하는 데에는 한계가 있다. GPU 수만장 확보를 통해 AI 개발·고도화와 서비스에 필요한 기반을 만들어도 데이터 없이는 거대언어모델(LLM) 등 AI 성능 강화가 어려운 상황을 고려해야 한다는 지적이 나온다.
챗GPT와 같은 생성형 AI 서비스를 제공하기 위해서는 AI 모델·LLM 학습이 선행돼야 하고 이를 위한 양질의 충분한 학습용 데이터가 요구된다. 오픈AI의 과거 모델인 GPT-3 학습에만 파라미터(AI 작동에 영향을 미치는 외부 데이터) 1750억개가 투입됐다.
업계는 공공데이터 개방·학습용 데이터 시장 조성 등 충분한 AI 학습용 데이터셋 확보를 위한 제도적 지원이 필요하다고 보고 있다.
이와 함께 저작권 해결도 요구한다. 저작권법상 저작권 침해가 면제되는 '공정이용' 대상에 AI 학습용 데이터를 포함하는 방안 등 제도화가 필요하다는 의견이다.
복수의 AI업계 관계자는 “AI 학습을 위해 데이터를 사용하고 사후에 저작권을 검토할 수 없기 때문에 제한적으로 활용하는 게 기업의 현실”이라며 “그럼에도 관련 제도나 기준이 명확하지 않아 소송 당할 위험이 상존하는 상황을 고려, 정부가 관련 법·제도를 정비하고 양질의 데이터 확보를 지원해야 한다”고 말했다.
딥시크의 깜짝 성공 역시 파라미터(약 6710억개 규모) 등 충분한 데이터가 있었기에 가능했다고 평가된다. 한 대규모 다중과제 언어이해 평가(MMLU)에서 딥시크 'R1'이 90.9점을 받았는데 업스테이지 '솔라 프로'가 약 220억개의 파라미터로 81.4점을 기록, 국내 AI 기업도 충분한 학습용 데이터가 확보되면 글로벌 톱티어 경쟁이 가능할 것으로 예상된다.
이에 저작권 공정이용 외에도 충분한 AI 학습용 데이터 확보를 위한 '슈퍼 데이터셋'을 만들 수 있는 특수 목적의 데이터 신탁 제도나 데이터 협동조합 형태를 인정해주는 것과 같은 법·제도를 검토해야 한다는 게 전문가 조언이다.
차경진 한양대 교수(비즈니스인포메틱스학과장)는 “우리나라에서 AI 경쟁력을 높이기 위한 데이터 확충 전략이나 국가 차원의 데이터 연합 모델 등에 대한 논의가 상대적으로 부족한 실정”이라며 “기업이 AI 학습에 데이터를 적극 활용함과 동시에 개인정보와 저작권을 보호할 수 있는 안전장치를 함께 제시할 수 있도록 제도 개선이 이뤄져야 한다”고 강조했다.
박종진 기자 truth@etnews.com
![[청년발언대] 창작자의 권리 vs AI의 발전: 공존을 위한 방안](https://www.youthdaily.co.kr/data/photos/20250208/art_17400356770637_58c762.jpg)

![[ISDP 2025] 홍석범 크래프톤 CISO “기업 보안 위한 핵심 전략” 제시](https://www.dailysecu.com/news/photo/202502/163970_192215_918.jpg)
![AI·바이오 투자 확대되고 있지만…IT 스타트업은 생존 갈림길 [AI 프리즘*주간 스타트업 창업자 뉴스]](https://newsimg.sedaily.com/2025/02/23/2GP2XQTBZY_1.jpg)
![연구비도 부족한데 세금까지…이럴 땐 ‘R&D 공제 사전심사’ [D:로그인]](https://cdnimage.dailian.co.kr/news/202502/news_1740120171_1464694_m_1.jpeg)
![[ISDP 2025] KISA 장웅태 선임 “해커들, SQL인젝션·웹쉘 업로드·파라미터 변조 공격으로 개인정보 유출”](https://www.dailysecu.com/news/photo/202502/163967_192208_441.jpg)